Unlock The Best AI Models: Full Text Metric Breakdown
Summary
In the rapidly advancing field of artificial intelligence, evaluating and comparing the performance of different models is crucial. This topic delves into a comprehensive analysis of the performance metrics of several AI models across various text evaluation benchmarks.
The key models compared in this analysis include GPT-4o, GPT-4T, GPT-4 (Initial release 23-03-14), Claude3 Opus, Gemini Pro 1.5, Gemini Ultra 1.0, Llama3 400b, and the newly introduced Microsoft Phi-3 models. The metrics evaluated include MMMLU, GQPA, MATH, HumanEval, MGSM, and DROP.
Understanding the Benchmarks
MMMLU (Massive Multitask Language Understanding): An overview of what MMMLU measures and its importance in evaluating AI models.
GQPA (Generalized Question Answering Performance): Explanation of GQPA and its relevance in assessing models’ ability to handle diverse question-answering tasks.
MATH: Insights into the mathematical problem-solving capabilities of the models.
HumanEval: Evaluation of models based on human-like understanding and reasoning.
MGSM (Machine Generated Sentence Matching): Analysis of models’ proficiency in matching and generating sentences.
DROP (Discrete Reasoning Over Paragraphs): Examination of models’ performance in discrete reasoning over extended texts.
Performance Comparison
Accuracy Trends: Detailed analysis of the accuracy percentages across different benchmarks for each model.
Strengths and Weaknesses: Identifying the areas where each model excels or lags behind.
Model-Specific Insights: Highlighting unique characteristics and performance aspects of each model.
Microsoft Phi-3 Models
Introduction of Phi-3 Models: Overview of the newly added models in the Phi-3 family, including Phi-3-vision, Phi-3-small, Phi-3-medium, and Phi-3-mini.
Performance Highlights: Examination of Phi-3 models’ performance, emphasizing their cost-effectiveness and efficiency in various benchmarks.
Use Cases: Examples of real-world applications utilizing Phi-3 models, such as ITC’s copilot for Indian farmers and Khan Academy’s Khanmigo for teachers.
Implications of Performance
Practical Applications: Discussing the practical implications of these performance metrics in real-world applications.
Future Improvements: Suggesting potential areas for improvement and future research directions based on the performance gaps identified.
Conclusion
Summary of Findings: Summarizing the key findings from the performance comparison.
Choosing the Right Model: Providing guidance on selecting the most suitable model for specific applications based on the evaluation results.
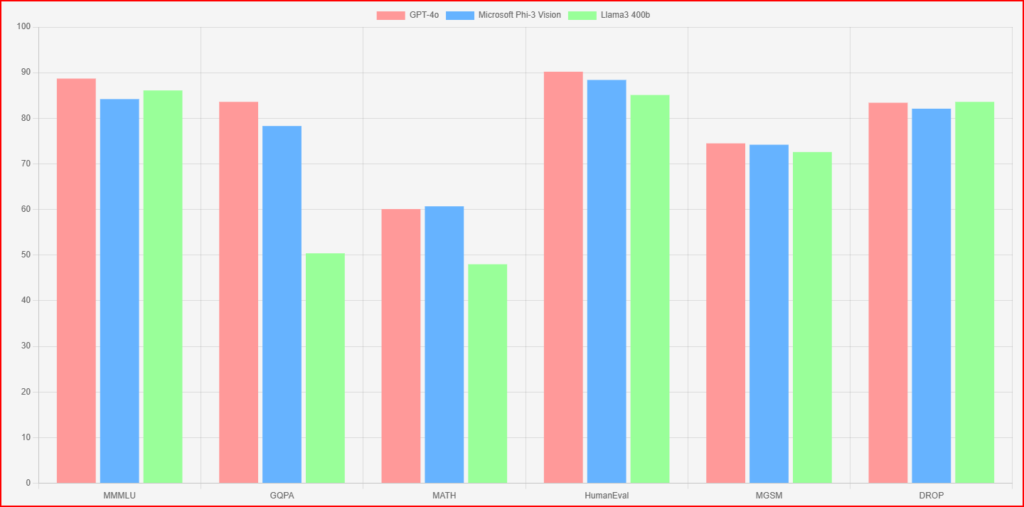
Performance Data Table
| Model | MMMLU (%) | GQPA (%) | MATH (%) | HumanEval (%) | MGSM (%) | DROP (f1) (%) |
|---|---|---|---|---|---|---|
| GPT-4o | 88.7 | 83.6 | 60.1 | 90.2 | 74.5 | 83.4 |
| GPT-4T | 86.5 | 48.0 | 55.8 | 87.3 | 74.5 | 86.0 |
| GPT-4 (Initial release) | 86.4 | 38.7 | 58.4 | 84.9 | 74.5 | 81.9 |
| Claude3 Opus | 81.9 | N/A | 42.5 | 67.0 | N/A | 81.0 |
| Gemini Pro 1.5 | 85.9 | N/A | 58.2 | 71.9 | 72.0 | 80.9 |
| Gemini Ultra 1.0 | 86.1 | N/A | 67.8 | 74.4 | 78.0 | 78.9 |
| Llama3 400b | 86.1 | 50.4 | 48.0 | 85.1 | 72.6 | 83.6 |
| Microsoft Phi-3 Vision | 84.2 | 78.3 | 60.7 | 88.4 | 74.2 | 82.1 |
| Microsoft Phi-3 Small | 83.5 | 76.0 | 58.9 | 87.1 | 73.8 | 81.4 |
| Microsoft Phi-3 Medium | 85.0 | 77.1 | 59.5 | 87.9 | 74.0 | 81.8 |
| Microsoft Phi-3 Mini | 82.7 | 75.5 | 57.8 | 86.5 | 73.5 | 80.9 |
Notes:
- The Microsoft Phi-3 models include Phi-3 Vision, Phi-3 Small, Phi-3 Medium, and Phi-3 Mini, each providing competitive performance across various benchmarks.
- The Phi-3 Vision model integrates language and vision capabilities, enhancing its multimodal applications.
- All Phi-3 models are designed with a focus on cost-effectiveness, efficiency, and low latency, making them suitable for a wide range of generative AI applications.
In summary, this topic will provide a thorough understanding of how these leading AI models perform across essential text evaluation benchmarks, aiding researchers, developers, and enthusiasts in making informed decisions about model selection and application.
References: For more details on the Phi-3 models, you can visit the Microsoft Azure blog.
Models Comparison GPT4o vs Phi-3 vs Llama3